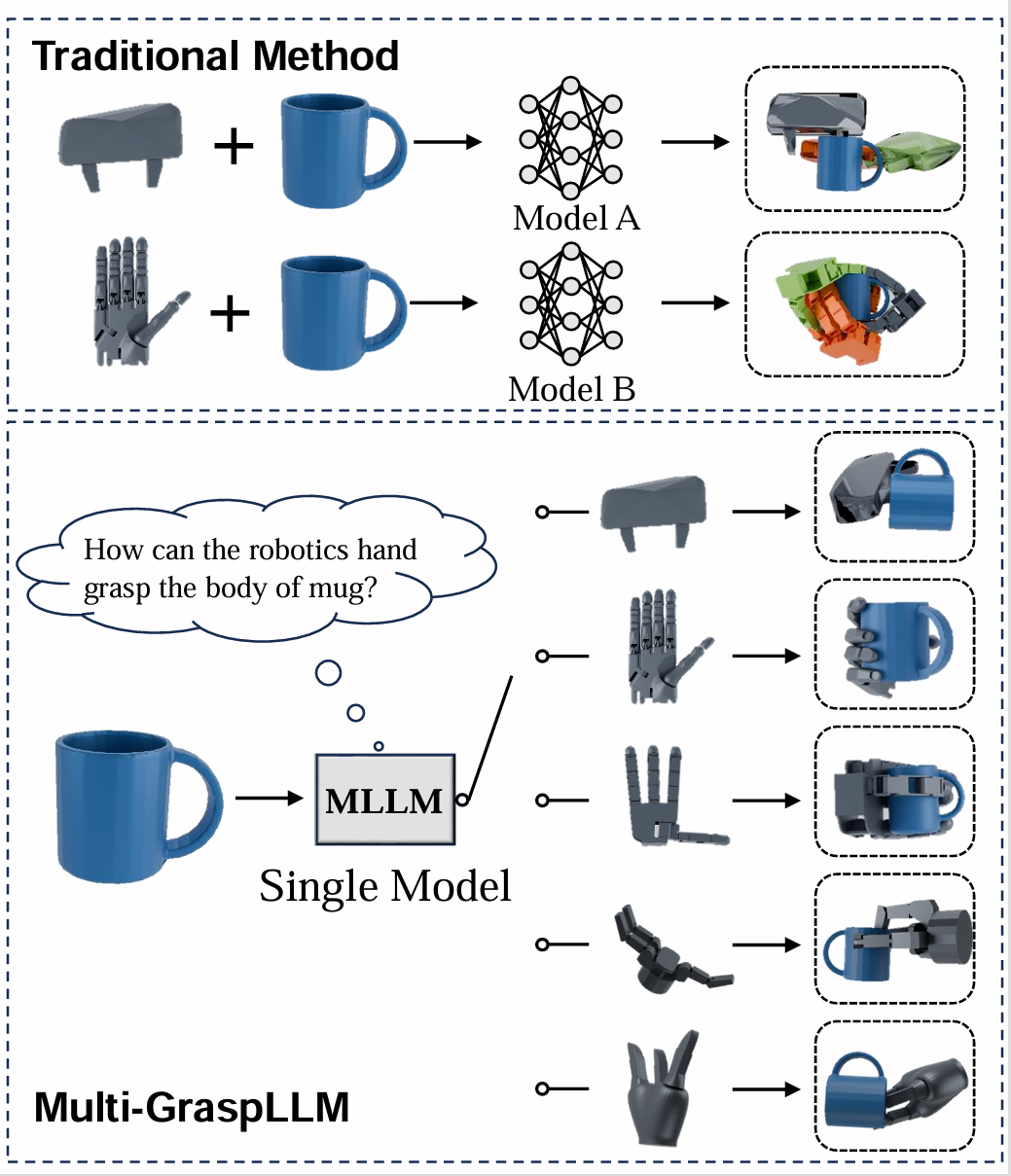
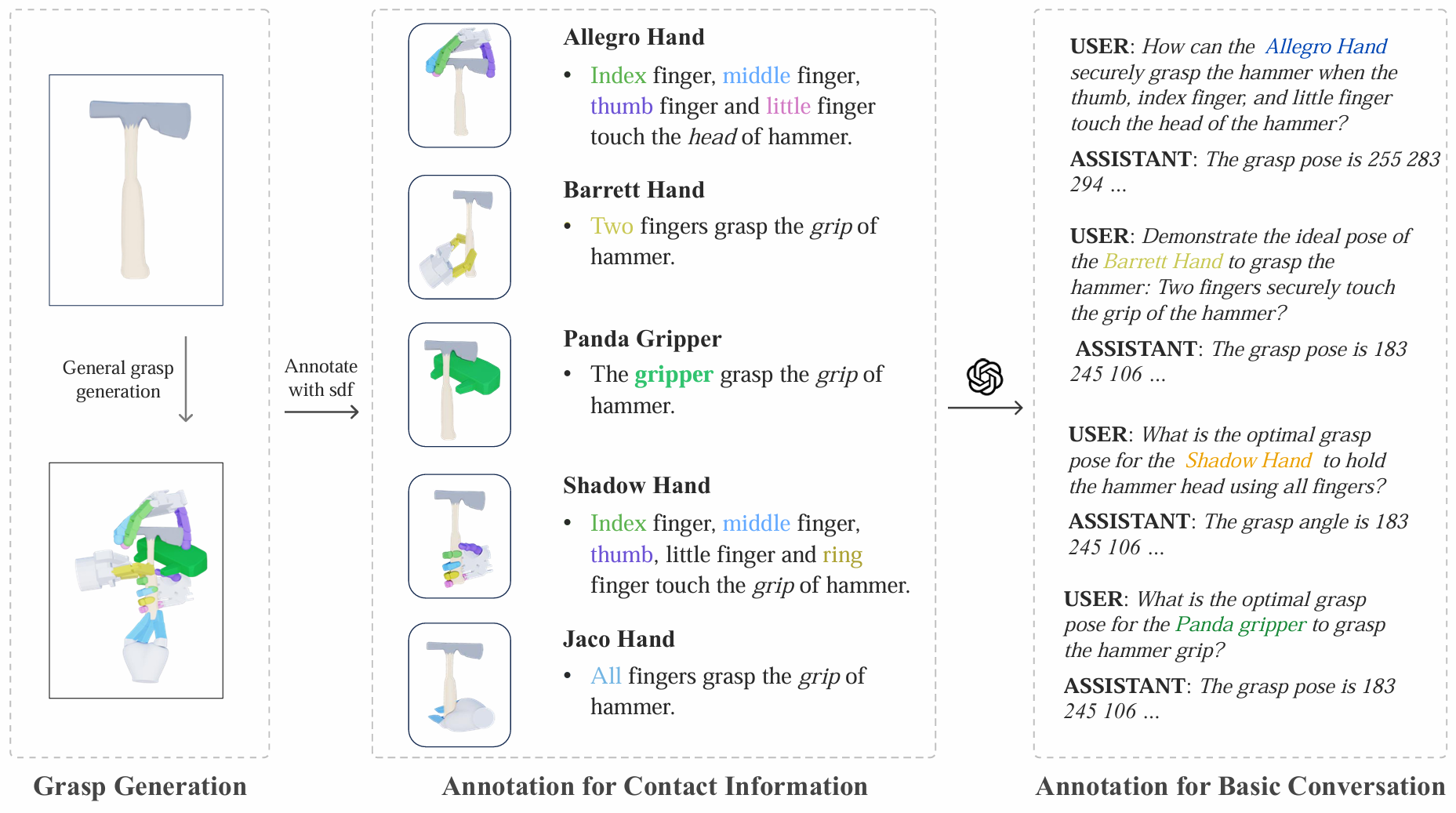
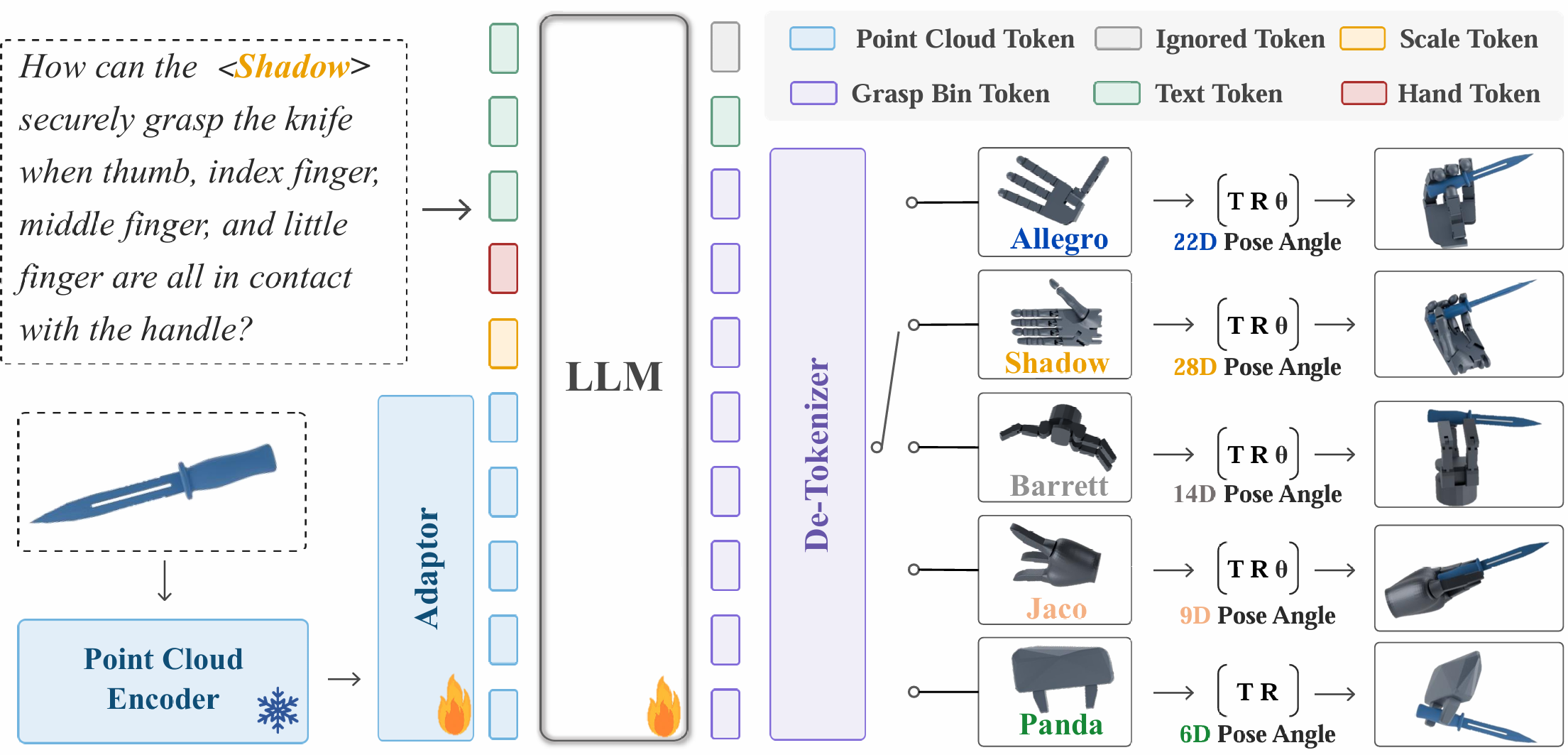
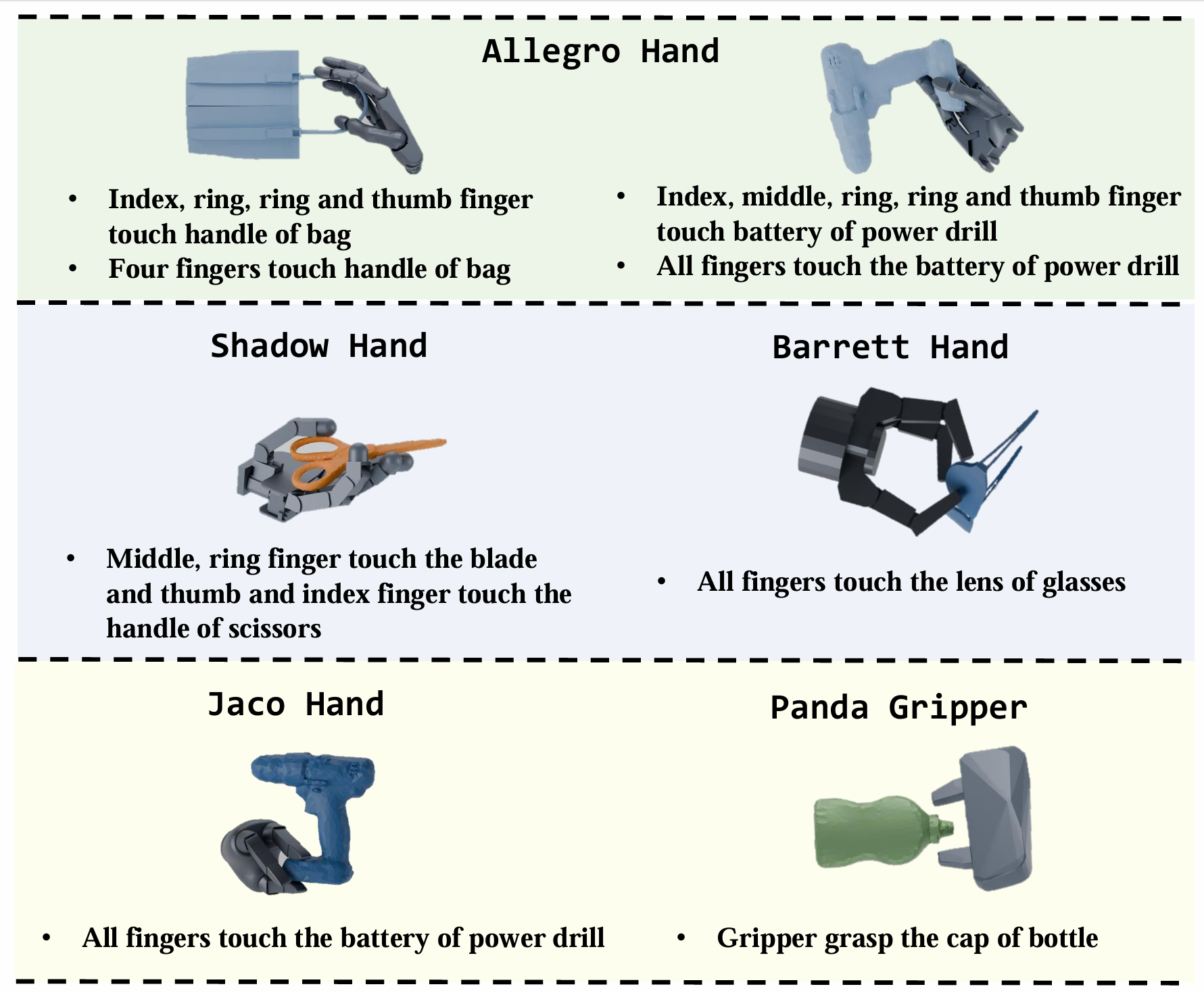
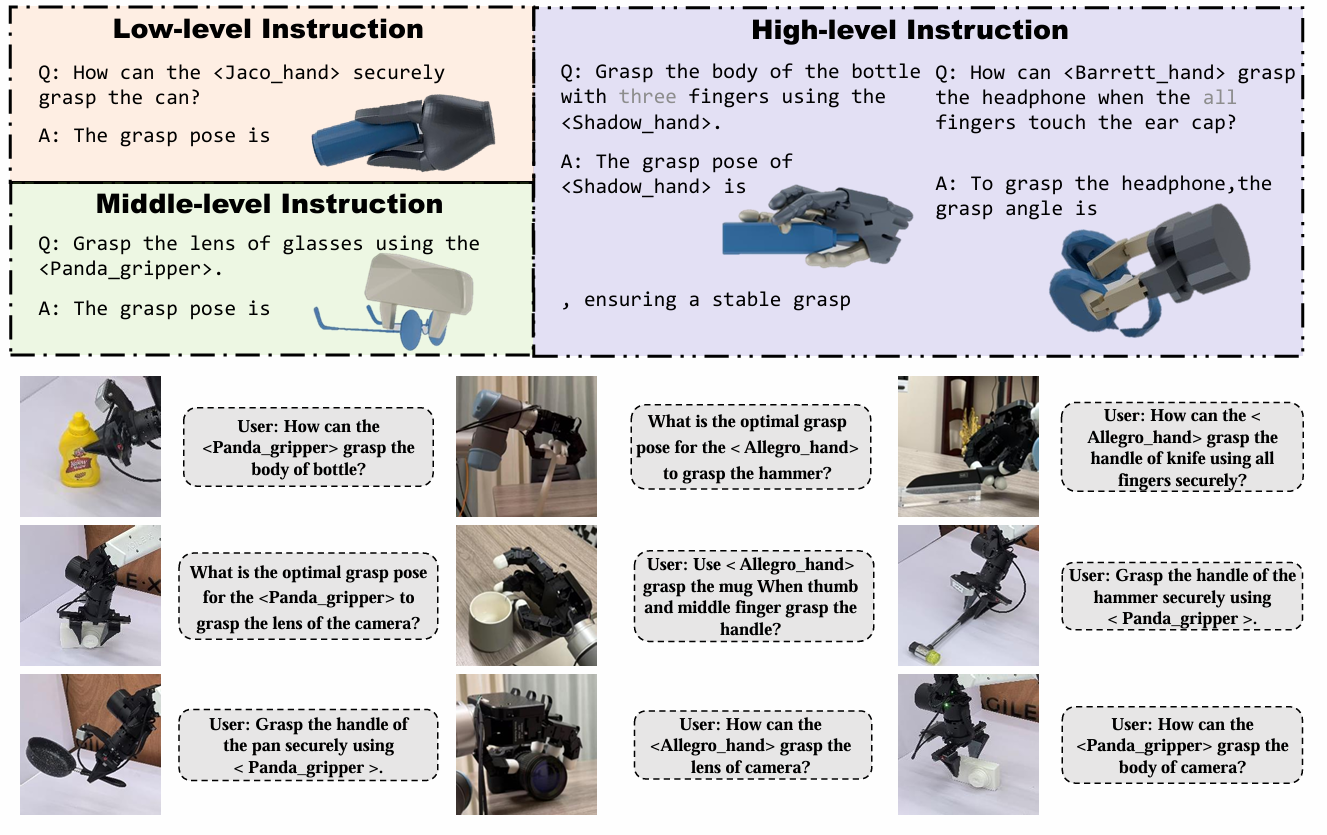
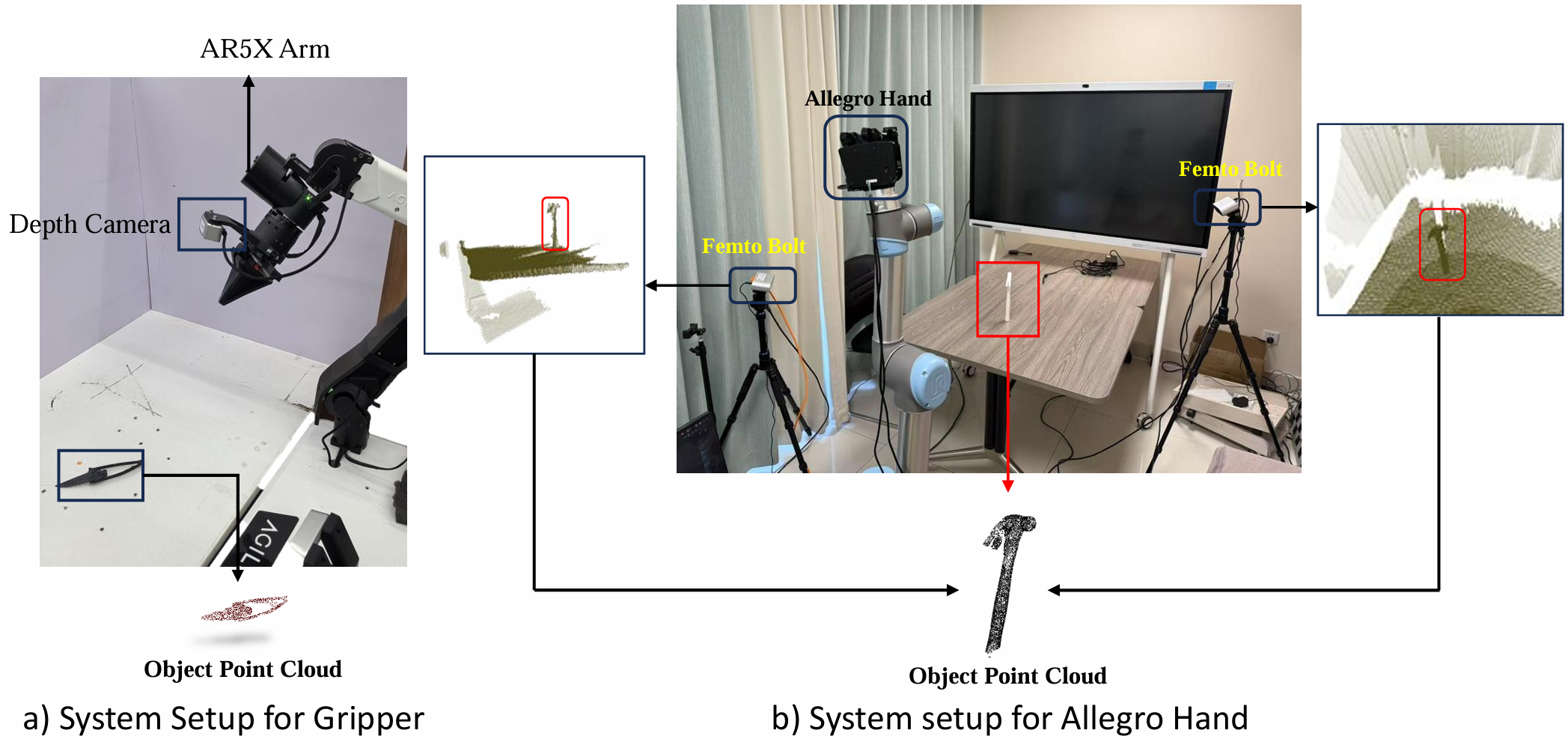
Multi-hand semantic grasp generation aims to generate feasible and semantically appropriate grasp poses for different robotic hands based on natural language instructions. Although the task is highly valuable, due to the lack of multi-hand grasp datasets with fine-grained contact description between robotic hands and objects, it is still a long-standing difficult task. In this paper, we present Multi-GraspSet, the first large-scale multi-hand grasp dataset with automatically contact annotations. Based on Multi-GraspSet, we propose Multi-GraspLLM, a unified language-guided grasp generation framework. It leverages large language models (LLM) to handle variable-length sequences, generating grasp poses for diverse robotic hands in a single unified architecture. Multi-GraspLLM first aligns the encoded point cloud features and text features into a unified semantic space. It then generates grasp bin tokens which are subsequently converted into grasp pose for each robotic hand via hand-aware linear mapping. The experimental results demonstrate that our approach significantly outperforms existing methods in both real-world experiments and simulator.